Specifying Upstream Dependencies¶
Results from a task can be provided to other tasks (or subflows) as upstream dependencies. Prefect uses upstream dependencies in two ways:
- To populate dependency arrows in the flow run graph
- To determine execution order for concurrently submitted units of work that depend on each other
Tasks vs. other functions
Only results from tasks inform Prefect's ability to determine dependencies. Return values from functions without task decorators, including subflows, do not carry the same information about their origin as task results.
When using non-sequential task runners such as the ConcurrentTaskRunner or DaskTaskRunner, the order of execution for submitted tasks is not guaranteed unless their dependencies are specified.
For example, compare how tasks submitted to the ConcurrentTaskRunner behave with and without upstream dependencies by clicking on the tabs below.
@flow(log_prints=True) # Default task runner is ConcurrentTaskRunner
def flow_of_tasks():
# no dependencies, execution is order not guaranteed
first.submit()
second.submit()
third.submit()
@task
def first():
print("I'm first!")
@task
def second():
print("I'm second!")
@task
def third():
print("I'm third!")
Flow run 'pumpkin-puffin' - Created task run 'first-0' for task 'first'
Flow run 'pumpkin-puffin' - Submitted task run 'first-0' for execution.
Flow run 'pumpkin-puffin' - Created task run 'second-0' for task 'second'
Flow run 'pumpkin-puffin' - Submitted task run 'second-0' for execution.
Flow run 'pumpkin-puffin' - Created task run 'third-0' for task 'third'
Flow run 'pumpkin-puffin' - Submitted task run 'third-0' for execution.
Task run 'third-0' - I'm third!
Task run 'first-0' - I'm first!
Task run 'second-0' - I'm second!
Task run 'second-0' - Finished in state Completed()
Task run 'third-0' - Finished in state Completed()
Task run 'first-0' - Finished in state Completed()
Flow run 'pumpkin-puffin' - Finished in state Completed('All states completed.')
@flow(log_prints=True) # Default task runner is ConcurrentTaskRunner
def flow_of_tasks():
# with dependencies, tasks execute in order
first_result = first.submit()
second_result = second.submit(first_result)
third.submit(second_result)
@task
def first():
print("I'm first!")
@task
def second(input):
print("I'm second!")
@task
def third(input):
print("I'm third!")
Flow run 'statuesque-waxbill' - Created task run 'first-0' for task 'first'
Flow run 'statuesque-waxbill' - Submitted task run 'first-0' for execution.
Flow run 'statuesque-waxbill' - Created task run 'second-0' for task 'second'
Flow run 'statuesque-waxbill' - Submitted task run 'second-0' for execution.
Flow run 'statuesque-waxbill' - Created task run 'third-0' for task 'third'
Flow run 'statuesque-waxbill' - Submitted task run 'third-0' for execution.
Task run 'first-0' - I'm first!
Task run 'first-0' - Finished in state Completed()
Task run 'second-0' - I'm second!
Task run 'second-0' - Finished in state Completed()
Task run 'third-0' - I'm third!
Task run 'third-0' - Finished in state Completed()
Flow run 'statuesque-waxbill' - Finished in state Completed('All states completed.')
Determination methods¶
A task or subflow's upstream dependencies can be inferred automatically via its inputs, or stated explicitly via the wait_for parameter.
Automatic¶
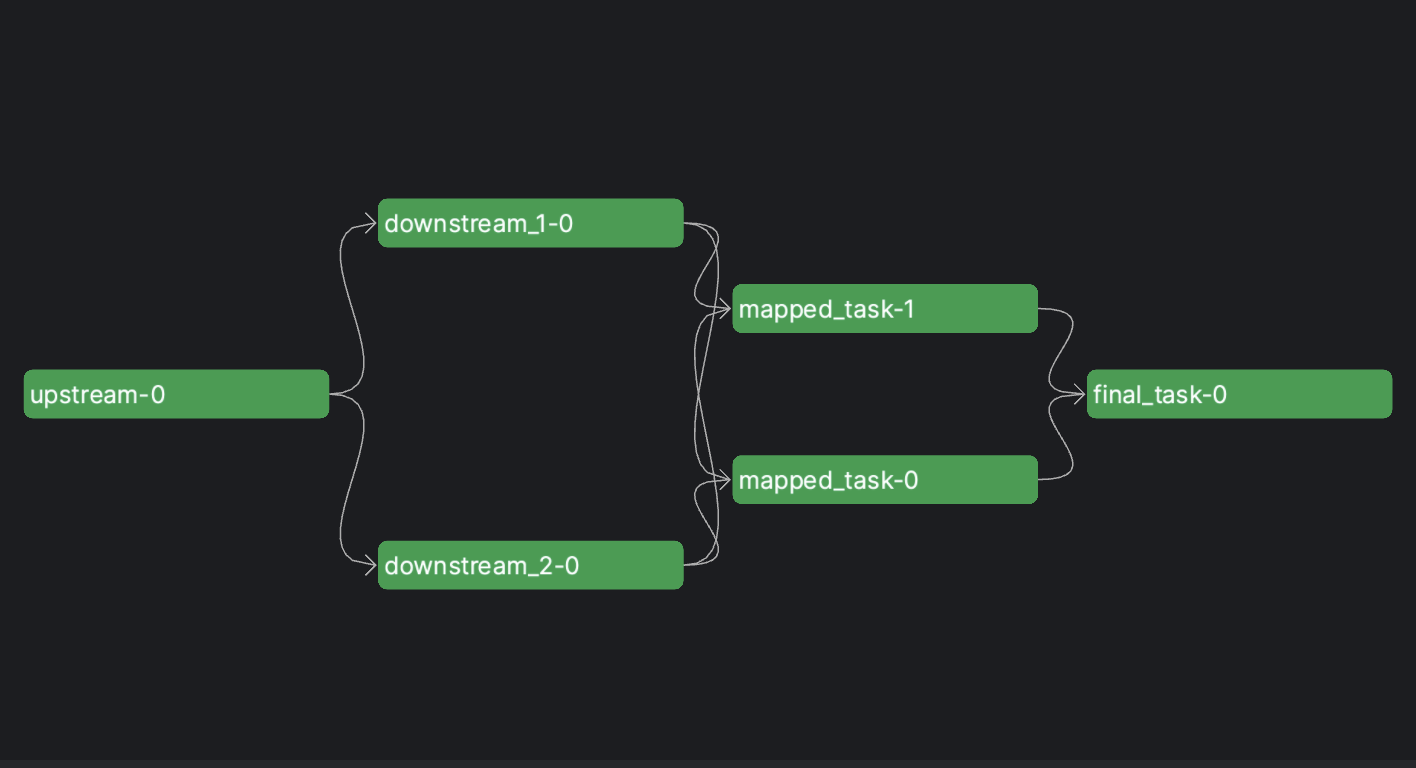
When a result from a task is used as input for another task, Prefect automatically recognizes the task that result originated from as an upstream dependency.
This applies to every way you can run tasks with Prefect, whether you're calling the task function directly, calling .submit(), or calling .map(). Subflows similarly recognize tasks results as upstream dependencies.
from prefect import flow, task
@flow(log_prints=True)
def flow_of_tasks():
upstream_result = upstream.submit()
downstream_1_result = downstream_1.submit(upstream_result)
downstream_2_result = downstream_2.submit(upstream_result)
mapped_task_results = mapped_task.map([downstream_1_result, downstream_2_result])
final_task(mapped_task_results)
@task
def upstream():
return "Hello from upstream!"
@task
def downstream_1(input):
return input
@task
def downstream_2(input):
return input
@task
def mapped_task(input):
return input
@task
def final_task(input):
print(input)

Manual¶
Tasks that do not share data can be informed of their upstream dependencies through the wait_for parameter. Just as with automatic dependencies, this applies to direct task function calls, .submit(), .map(), and subflows.
Differences with .map()
Manually defined upstream dependencies apply to all tasks submitted by .map(), so each mapped task must wait for all upstream dependencies passed into wait_for to finish. This is distinct from automatic dependencies for mapped tasks, where each mapped task must only wait for the upstream tasks whose results it depends on.
from prefect import flow, task
@flow(log_prints=True)
def flow_of_tasks():
upstream_result = upstream.submit()
downstream_1_result = downstream_1.submit(wait_for=[upstream_result])
downstream_2_result = downstream_2.submit(wait_for=[upstream_result])
mapped_task_results = mapped_task.map([1, 2], wait_for=[downstream_1_result, downstream_2_result])
final_task(wait_for=mapped_task_results)
@task
def upstream():
pass
@task
def downstream_1():
pass
@task
def downstream_2():
pass
@task
def mapped_task(input):
pass
@task
def final_task():
pass
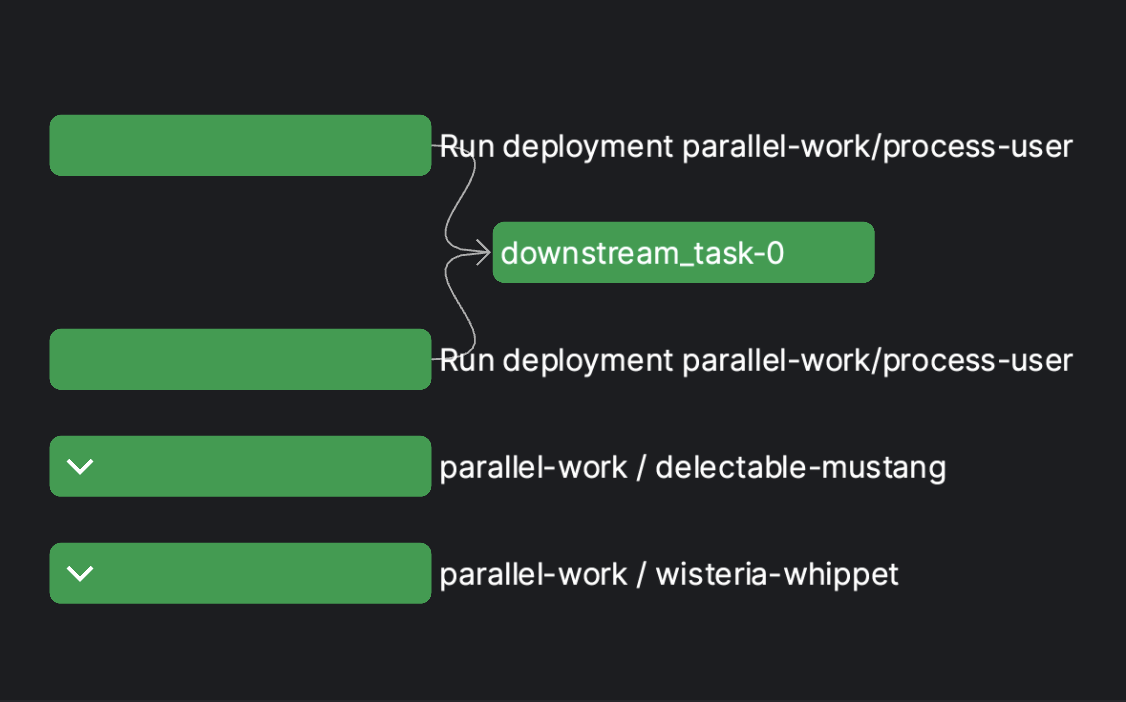
Deployments as dependencies¶
For more complex workflows, parts of your logic may require additional resources, different infrastructure, or independent parallel execution. A typical approach for addressing these needs is to execute that logic as separate deployment runs from within a flow.
Composing deployment runs into a flow so that they can be treated as upstream dependencies is as simple as calling run_deployment from within a task.
Given a deployment process-user of flow parallel-work, a flow of deployments might look like this:
from prefect import flow, task
from prefect.deployments import run_deployment
@flow
def flow_of_deployments():
deployment_run_1 = run_deployment_task.submit(
flow_name="parallel-work",
deployment_name="process-user",
parameters={"user_id": 1},
)
deployment_run_2 = run_deployment_task.submit(
flow_name="parallel-work",
deployment_name="process-user",
parameters={"user_id": 2},
)
downstream_task(wait_for=[deployment_run_1, deployment_run_2])
@task(task_run_name="Run deployment {flow_name}/{deployment_name}")
def run_deployment_task(
flow_name: str,
deployment_name: str,
parameters: dict
):
run_deployment(
name=f"{flow_name}/{deployment_name}",
parameters=parameters
)
@task
def downstream_task():
print("I'm downstream!")
By default, deployments started from run_deployment will also appear as subflows for tracking purposes. This behavior can be disabled by setting the as_subflow parameter for run_deployment to False.